
بهروزرسانی رتبه بندی TF مبتنی بر کِرس در راستای سرعت بهروزرسانیهای اخیر گوگل است. که امکان توسعه سریع الگوریتمهای قدرتمند رتبهبندی و اسپم را فراهم میکند.
گوگل از انتشار فناوری پیشرفتهای خبر داده است که تحقیق و توسعه الگوریتمهای جدید را آسانتر و سریعتر انجام میدهد. این فناوری به گوگل کمک میکند تا به سرعت الگوریتمهای جدید آنتی اسپم ایجاد کند، الگوریتمهای مربوط به پردازش زبان طبیعی و رتبهبندی را بهبود دهد و بتواند آنها را سریعتر از همیشه وارد مرحله تولید کند.
بهبود رتبه بندی TF همزمان با تاریخ آخرین به روزرسانی گوگل
این مورد بسیار حائز اهمیت است، زیرا گوگل چندین الگوریتم مقابله با اسپم و دو آپدیت برای الگوریتم اصلی را در ژوئن و جولای 2021 ارائه کرده است. این توسعهها به طور مستقیم پس از انتشار این فناوری جدید در ماه مه 2021 انجام شد.
این زمانبندی میتواند تصادفی باشد، اما با توجه به مواردی که نسخه جدید رتبهبندی TF مبتنی بر کرس انجام میدهد، درک اینکه چرا گوگل سرعت انتشار بهروزرسانیهای جدید الگوریتم رتبهبندی را افزایش داده است حائز اهمیت خواهد بود.
نسخه جدید رتبهبندی-TF مبتنی بر کِرس
گوگل نسخه جدیدی از رتبه بندی TFرا معرفی کرده است که میتواند برای بهبود یادگیری عصبی برای الگوریتمهای رتبهبندی و همچنین الگوریتمهای پردازش زبان طبیعی مانند الگوریتم برت استفاده شود.
این یک روش قدرتمند برای ایجاد الگوریتمهای جدید و توسعه الگوریتمهای موجود است، پس میتوان گفت که فوقالعاده سریع کار میکند.
بیشتر بخوانید : هزینه سئو سایت چگونه محاسبه می شود؟
رتبه بندی TensorFlow
به گفته گوگل، تنسورفلو یک پلتفرم یادگیری1 ماشین است.
در یک ویدیوی یوتیوب در سال 2019، اولین نسخه رتبهبندی تنسورفلو به شرح زیر بیان شد:
اولین کتابخانه یادگیری عمیق منبع باز برای یادگیری رتبهبندی (LTR) در مقیاس مناسب.
نوآوری پلتفرم رتبهبندی TF این بود که نحوه رتبهبندی اسناد مربوطه را تغییر داد.
اسناد مرتبط ازقبل با یکدیگر مقایسه شدند که به آن رتبهبندی دو به دو (زوجی) میگویند. احتمال مرتبط بودن یک سند به یک پرس و جو با احتمال آیتم دیگر مقایسه شد.
این مقایسه بین دو سند انجام شد و مقایسه کل لیست نیست.
نوآوری رتبهبندی TF این است که امکان مقایسه کل لیست اسناد را در یک زمان فراهم میکند، که به آن امتیازبندی چند آیتمی می گویند. این رویکرد به تصمیمگیری بهتر رتبهبندی کمک میکند.
بهبود رتبهبندی TF امکان توسعه سریع الگوریتمهای جدید قدرتمند را فراهم میکند.
مقاله گوگل که در وبلاگ هوش مصنوعی آنها منتشر شده است میگوید:
رتبهبندی TF نسخه مهمی است که فرآیند مدلهای یادگیری رتبهبندی (LTR) را آسانتر میکند و آنها را سریعتر وارد مرحله بهرهبرداری (تولید) میکند.
این بدان معناست که گوگل میتواند الگوریتمهای جدیدی ایجاد کرده و آنها را سریعتر از همیشه به موتور جستجو اضافه کند.
در مقاله آمده است:
مدل رتبهبندی بومی کرس ما دارای یک طراحی جریان کار کاملا جدید است، که شامل ModelBuilder انعطافپذیر، یک DatasetBuilder برای تنظیم دادههای آموزش، و یک خط لوله برای آموزش مدل با مجموعه داده ارائهشده است.
این مولفهها ساخت مدل LTR سفارشی، و بررسی سریع ساختارهای مدل جدید برای تولید و تحقیق را آسانتر میکنند.
رتبهبندی TF – الگوریتم برت
هنگامی که یک پژوهش یا مقاله تحقیقاتی بیان میکند که نتایج تاحدی بهتر بوده است، و به نکاتی اشاره میکند و میگوید که به تحقیقات بیشتری نیاز است، این نشان میدهد که الگوریتم مورد بحث ممکن است کاربردی نباشد، زیرا آماده نیست یا جای توسعه ندارد.
اما برای TFR-BERT (ترکیبی از رتبهبندی TF و برت) اینگونه نیست.
برت یک روش یادگیری ماشین برای پردازش زبان طبیعی است. راهی برای درک پرسوجوهای جستجو و محتوای صفحه وب است.
برت یکی از مهمترین بهروزرسانیهای گوگل و بینگ در چند سال گذشته است.
این مقاله بیان میکند که ترکیب رتبهبندی TF با برت، پیشرفت قابل توجهی در بهینهسازی ترتیب ورودیهای لیست ایجاد کرده است.
این گزارش-که نتایج آن نیز قابلتوجه بود- مهم است. زیرا رتبهبندی TF مبتنی بر کرس، برت را قویتر کرده است.
به گفته گوگل:
تجربه ما نشان میدهد که این معماری TFR-BERT پیشرفتهای قابل توجهی را در عملکرد مدل زبان از پیشآموزش دیده ارائه داده است و منجر به عملکرد پیشرفته برای چندین وظیفه رتبهبندی محبوب شده است.
بشتر بدانید : سئو چیست؟
رتبهبندی TF و GAMها
نوع دیگری از الگوریتم، به نام مدلهای جمعی تعمیمیافته (GAMs)، رتبهبندی TF را بهبود داده است و حتی نسخه قویتر از نسخه اصلی توسعه داده است.
یکی از مزایای مهم این الگوریتم، شفافیت آن است، زیرا همه مواردی که در رتبهبندی نقش دارند، قابلمشاهده و قابل درک هستند.
گوگل اهمیت شفافیت را اینگونه بیان کرد:
“شفافیت و تفسیرپذیری عوامل مهم استقرار مدلهای LTR در سیستمهای رتبهبندی هستند که میتوانند در تعیین نتایج فرآیندهایی مانند ارزیابی، هدف قراردادن تبلیغات یا هدایت تصمیمات نقش داشته باشند.”
در اینگونه موارد، سهم هر ویژگی فردی در رتبهبندی نهایی باید قابل بررسی و قابل درک باشد تا شفافیت، پاسخگویی و منصفانه بودن نتایج تضمین شود.
مسئله GAMها این است که نحوه استفاده از این فناوری برای رتبهبندی مشخص نیست. برای حل این مسئله و استفاده از GAM در رتبهبندی، از رتبهبندی TF برای رتبهبندی عصبی در مدلهای جمعی تعمیمیافته (GAM) استفاده شد که برای رتبهبندی صفحات وب بازتر است.
گوگل این را یادگیری رتبهبندی قابل تفسیر مینامد.
در اینجا، متن مقاله AI گوگل آمده است:
برای این منظور، ما رتبهبندی عصبی مدل GAM را توسعه دادیم که توسعهای از مدلهای جمعی تعمیمیافته برای مسائل رتبهبندی است.
برخلاف GAMهای استاندارد، رتبه بندی عصبی مدل GAM میتواند ویژگیهای آیتمهای رتبهبندیشده و ویژگیهای زمینه (به عنوان مثال، پرس و جو یا پروفایل کاربر) را برای استخراج یک مدل جمع و جور و قابل تفسیر در نظر بگیرد.
برای مثال، در شکل زیر، با استفاده از رتبهبندی عصبی GAM ، نحوه فاصله، قیمت و ارتباط در یک دستگاه کاربری معین مشخص میشود، و میتواند به رتبهبندی نهایی هتل کمک کند.
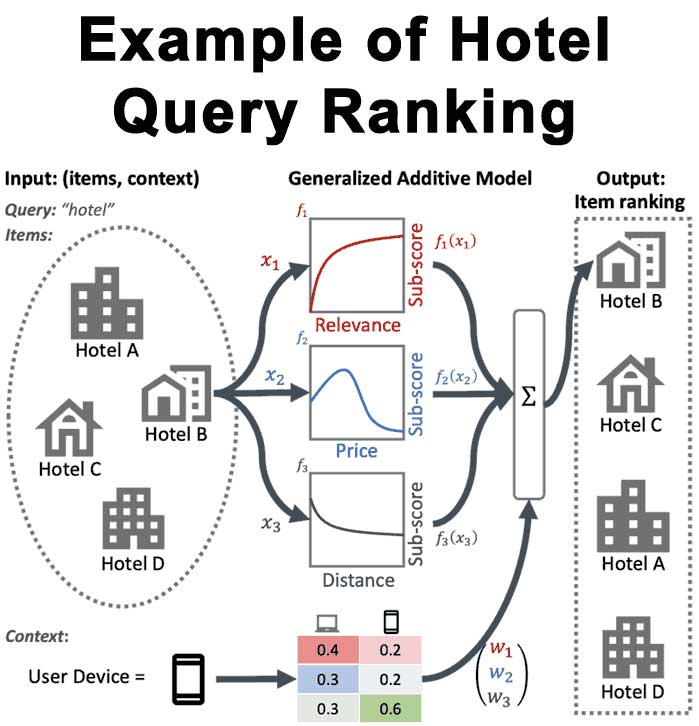
GAMهای دارای رتبهبندی عصبی اکنون به عنوان بخشی از رتبهبندی TF در دسترس هستند.
از جف کویل، بنیانگذار فناوری بهینهسازی محتوا AI MarketMuse (@MarketMuseCo)، در مورد رتبهبندی TF و GAMها سوال شد.
جفری، که دارای پیشینه علوم کامپیوتر و چندین دهه تجربه در بازاریابی جستجو است، خاطرنشان کرد که GAMها یک فناوری مهم هستند و بهبود آن نیز رویداد مهمی بوده است.
آقای کویل اظهار داشت:
من زمان زیادی صرف تحقیق در مورد نوآوری رتبهبندی عصبی GAMها و تأثیر احتمالی آن بر تجزیه و تحلیل زمینه (برای پرس و جوها) کردهام که از اهداف بلندمدت تیمهای امتیازدهی گوگل بوده است.
RankGAM عصبی و فناوریهای مرتبط با آن سلاحهای مهلکی برای شخصیسازی (به ویژه اطلاعات کاربر و اطلاعات زمینه، مانند مکان) و تجزیه و تحلیل قصد و اهداف هستند.
با استفاده از نمونه عمومی دردسترس keras_dnn_tfrecord.py، نگاهی اجمالی به نوآوری در سطح اولیه خواهیم داشت.
توصیه میکنم که همه این کد را بررسی کنند.
عملکرد بهتر درخت تصمیم افزایش گرادیان (BTDT)
رقابت با استاندارد الگوریتم مهم است، زیرا این بدان معناست که رویکرد جدید دستاوردی است که کیفیت نتایج جستجو را بهبود میبخشد.
در این مورد، استاندارد، درخت تصمیم گیری افزایش گرادیان (GBDT)، یک روش یادگیری ماشین است که مزیتهای متعددی دارد.
اما گوگل توضیح میدهد که GBDTها معایبی نیز دارند:
GBDTها نمیتوانند به طور مستقیم در فضاهای ویژگی گسسته بزرگ مانند متن سند خام اعمال شوند. آنها مقیاسپذیری کمتری نسبت به مدلهای رتبهبندی عصبی دارند.
در مقالهای با عنوان، آیا رتبهبندهای عصبی نسبت به درختان تصمیم افزایش گرادیان عملکرد بهتری دارند؟ محققان اظهار داشتند که یادگیری عصبی برای رتبهبندی مدلها بسیار پایینتر از اجرای مبتنی بر درخت است.
محققان گوگل از رتبهبندی جدید TF مبتنی بر کرس برای تولید مدل DASALC استفاده کردند.
DASALC مهم است، زیرا قادر به تطبیق یا پیشی گرفتن از خط مبنای فعلی است:
مدلهای ما قادر به مقایسه با خط مبنای مبتنی بر درخت هستند، و در عین حال، در رتبهبندی روشها، با اختلاف زیاد بهتر از یادگیری عصبی عمل میکنند. نتایج ما به عنوان معیار یادگیری عصبی برای رتبهبندی مدلها عمل میکند.
رتبهبندی TF مبتنی بر کرس توسعه الگوریتمهای رتبهبندی را سرعت میبخشد.
این سیستم جدید که سرعت تحقیق و توسعه سیستمهای رتبهبندی جدید را افزایش میدهد، شامل شناسایی اسپم برای رتبهبندی آنها در خارج از نتایج جستجو است.
جمعبندی مقاله به صورت زیر است:
در مجموع، ما معتقدیم که نسخه جدید رتبهبندی TF مبتنی بر کرس، انجام تحقیقات LTR عصبی و استقرار سیستمهای رتبهبندی از درجه تولید را آسانتر میکند.
گوگل با بهروزرسانیهای متعدد الگوریتم اسپم در طی چند ماه گذشته و 2 بهروزرسانی الگوریتم اصلی در طی دو ماه به نوآوری پرداختهاند.
توسعه این فناوریهای جدید بدین خاطر است که گوگل الگوریتمهای جدیدی را برای مقابله با اسپم و به طور کلی رتبهبندی وب سایتها انتشار داده است.